Kaldi: Uniform Segmentation
Goal
When decoding with pre-trained Aspire model I noticed that the audio with background noise gave us high error rate. When I looked at decoded text many words simply where missing. It was shown before that uniform segmentation can improve decoding results on long audio files that were decoded with Aspire model. I wanted to test that observation on our audio files, as our audio files are around 1 hour long.
Training data/test data/ pre-tained model
For testing I used captions from approximately 30K youtube videos [57,592,182 words]. I noticed that the text has approximately 200K duplicate lines.
Expected outcome
I am expecting to see some improvements in decoded text.
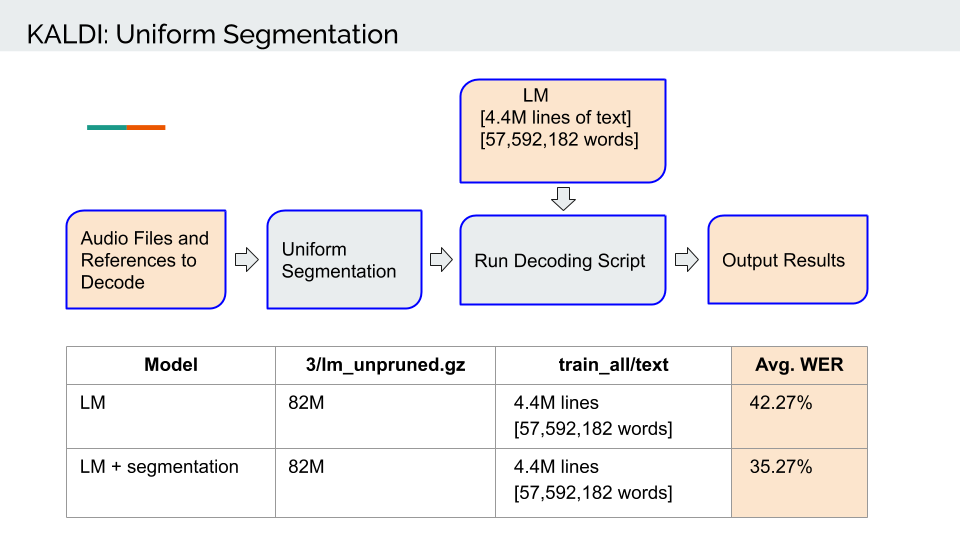
Results
I tested only on a single file that was 1 hour long. The file has very loud music in the background in the beginning and at the end of the recording. I observed ~7 point improvement in the final results.
What I Learned: Even when the model is trained with background noise it still can have a hard time with decoding audios with background noise and segmentation helps on long audio files.
KALDI: Notes on decoding with uniform segmentation:
1. # create by hand utt2spk
2. # create spk2utt file
utils/utt2spk_to_spk2utt.pl utt2spk > spk2utt
3. # create text and wav.scp
4. # get segments
utils/data/get_segments_for_data.sh data/test > data/test/segments
5. # copy text into a new folder
cp test/text test_segmented
6.
utils/data/get_uniform_subsegments.py --max-segment-duration=30 --overlap-duration=5 --max-remaining-duration=15 data/test/segments > data/test/uniform_sub_segments
7. # create features
steps/make_mfcc.sh --nj 1 --mfcc-config conf/mfcc_hires.conf data/test
8.
utils/data/subsegment_data_dir.sh data/test/ data/test/uniform_sub_segments data/test_segmented
9. # assumes one has a language model and graph
# https://npovey.github.io/update/2020/09/08/kaldi-basic-decoding.html
10. # decode
steps/online/nnet3/decode.sh --cmd utils/run.pl --nj 1 --acwt 1.0 --post-decode-acwt 10.0 exp/tdnn_7b_chain_online/graph_pp data/test_segmented exp/tdnn_7b_chain_online/decode_test
11. # splices the broken-up pieces together
# --frame-shift 0.01 or --frame-shift 0.03 all producing the same results
steps/get_ctm_fast.sh --cmd utils/run.pl --frame-shift 0.01 data/test_segmented exp/tdnn_7b_chain_online/graph_pp exp/tdnn_7b_chain_online/decode_test exp/tdnn_7b_chain_online/decode_test/score_10_0.0
12. # create "reco2file_and_channel" file
touch reco2file_and_channel
pico reco2file_and_channel
# 13 13 0
13. # concatenates the pieces of text and resolves bits that overlap in time...
utils/ctm/resolve_ctm_overlaps.py data/test_segmented/segments exp/tdnn_7b_chain_online/decode_test/score_10_0.0/ctm - | utils/convert_ctm.pl
data/test_segmented/segments data/test_segmented/reco2file_and_channel > exp/tdnn_7b_chain_online/decode_test/score_10_0.0/no_segments.ctm
14. # don't remember but this shouldn't work
#local/score.sh --cmd utils/run.pl data/test_segmented exp/tdnn_7b_chain_online/graph_pp exp/tdnn_7b_chain_online/decode_test
15. # write a script to convert ctm->text
cat no_segments.ctm | awk '{$1 = ""; $2 = ""; $3 = ""; $4 = ""; print $0}' > z.txt
cat z.txt | tr "\n" " " > z2.txt
16. #score
# You must slightly edit "z2.txt" to match the data/text
# remove word test at the top and add the matching file name as in data/text
. ./path.sh
compute-wer --text --mode=present ark:data/test/text ark:exp/tdnn_7b_chain_online/decode_test/score_10_0.0/z2.txt
#%WER 35.51 [ 3060 / 8617, 391 ins, 1030 del, 1639 sub ]
#or
compute-wer-bootci --mode=present ark:data/test/text ark:exp/tdnn_7b_chain_online/decode_test/score_10_0.0/z5.txt
17. # pipe through hyp_filter to remove "unk"
./wer_hyp_filter < exp/tdnn_7b_chain_online/decode_test/score_10_0.0/z2.txt > removed_unk.txt
18. score again
compute-wer --text --mode=present ark:data/test/text ark:exp/tdnn_7b_chain_online/decode_test/score_10_0.0/removed_unk.txt
#%WER 35.27 [ 3039 / 8617, 364 ins, 1116 del, 1559 sub ]
#%SER 100.00 [ 1 / 1 ]
#Scored 1 sentences, 0 not present in hyp.